 Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI
Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI Organizations, the ultimate way to manage your users and projects
Organizations, the ultimate way to manage your users and projects


(This article was originally published in php[architect] magazine, in two installments.)
As a general rule, lying to people is a bad idea. People don't like dishonesty. It's insulting to lie to a person and tends to destroy relationships both personal and professional.
But computer software isn't people (thank goodness). Virtually all software today is based on lies, very well-organized and effective lies. Lies make modern computer systems possible.
The latest generation of software deception is "containers." Containers are all the rage these days: They make hosting more flexible and reliable; they make development environments easier to set up; they're "like lightweight VMs"; and based on the marketing they also taste great and are less filling. But... what are they, really?
Here's the dirty little secret: They don't exist. In Linux, there is no such thing as a "container." It's all a lie. The technology that underpins Platform.sh's hosting is simply a careful combination of lies, all the way down to the microchip. That's the whole point!
To get to the truth of containers, we need to start unwrapping those lies and see how a modern Linux-based operating system actually works. Before we can talk about containers, we have to first talk about the very first lie of modern computing: multi-tasking.
What is a process?
At the most fundamental level, any modern computer is a rock (the CPU) that has been convinced to move electrons around in a specific way based on a long series of instructions. Those instructions are all very low-level operations, but a long string of such instructions form a program. And the current instruction being executed is tracked in a special slot called the "program counter" (PC).
Very often a program will need to wait if it’s trying to communicate with another part of the computer, like a network port or disk drive. In that time it's helpful for the CPU to be able to work on some other instructions while waiting. That lets the computer pretend (lie!) that it's running two programs "at the same time."
The hardware of the CPU has a special relationship with one particular program, called an operating system. That special program is always the first to start, and among other things is responsible for "context switching." At regular intervals, the CPU will "tick" and register what's known as a timer interrupt. That causes the CPU to stop what it's doing and load a specific set of instructions out of the operating system into its active memory, then continue. That specific set of instructions is known as the "timer interrupt handler." There are other types of interrupts and handlers as well that aren't relevant to us at the moment. The timer interrupt handler then picks a different program to load into the CPU's memory and lets it continue. That whole process can happen thousands of times a second, giving the illusion (lie!) that the computer is running multiple programs at once.
The part of the operating system responsible for that swapping in and out of different running programs is called the scheduler. And technically, each one of the running programs is called a process. In a system with multiple CPUs or multiple cores the same basic routine happens, but the scheduler has to keep track of multiple active instruction lists each with its own program counter.
As an aside, a multithreaded program is a single process that can be thought of as having more than one program counter pointing at different instructions in the same program/process. When the operating system context switches, it may activate one program counter or another within a given process.
What is virtual memory?
Of course, the programs don't know that they're all time-sharing the same CPU. And they definitely don't know that they're all sharing the same system memory. The program says to write to the memory at address 12345; but it doesn't really have address 12345. The operating system is there!
Instead, CPUs and operating systems conspire against processes and lie to them, letting them all think that they have a long list of contiguous memory addresses starting at 0. Every program thinks it has that, but it really has a series of small, mostly contiguous chunks of memory all over the physical memory space of the computer. The CPU translates the process-local memory address into the physical memory address and back again, with the program none the wiser. This concept is known as "virtual memory."
There are two key advantages to this memory lie-map: simplicity and security. From the program's point of view, having to keep track of which memory belongs to it and which memory belongs to some other program is way too complex and hard. The memory used by other programs could change at any moment, and no mortal programmer is going to be able to account for that manually. By abstracting that problem away, it frees up the programmer from trying to avoid inevitable memory management mistakes.
That mapping also provides a layer of security. Most of the time, one program reading another program's memory is a security hole, and being able to write into another program's memory certainly is. By not giving programs a way to even address each other's memory, it makes it much harder for one running program to corrupt another. (Harder, but not impossible. In languages with manual memory management, it's still possible to do with sloppy coding, which is one of the main sources of security problems in those languages.)
Process management
On a Unix-family operating system, processes are tracked in a hierarchy by what other process started them. Any process can ask the operating system to start another process or to "fork" the running process into two processes that can then proceed "in parallel." The operating system itself doesn't have a process per se, but can be thought of as process ID 0 (or PID 0). In Linux, PID 1 is a special process called init, which is responsible for managing all other processes below it. Various init programs have come and gone over the years, from the venerable sysvinit to runit, upstart, and systemd.
Conceptually, then, the memory space of a modern Linux system looks something like Figure 1.
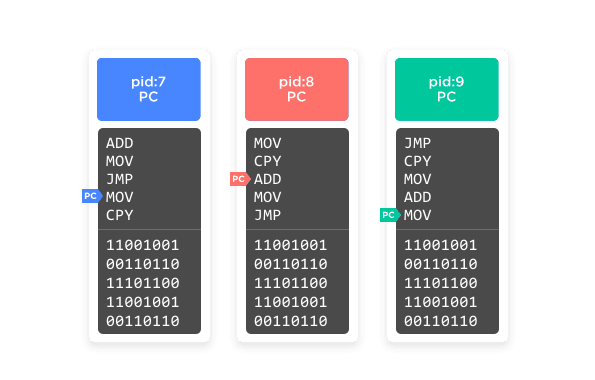
Figure 1
Each process has its own contained memory space and cannot directly touch any other process's memory space. It can, however, ask the operating system to pass a message to another process for it, which allows processes to communicate with each other. There are various mechanisms for that, but the most common is pipe files; that is, a fake file (lie!) that the operating system exposes that one process can write to in a stream and another process can read from in a stream. That abstraction allows a program to remain ignorant of whether the process it's talking to is on the same computer or on a different computer over the network.
What's important to note here is that every process can know about every other process. They all can ask the operating system for information about the computer they're running on, such as what file systems are available, what users are on the system and what permissions they have, what the host name of the computer is, what local or network devices are available, and so on. And the operating system will give the same answer to each process that asks.
Introducing Linux namespaces
Everything we've said up until now applies more or less the same to any reasonably modern operating system, give or take a few implementation details. The rest of this article is very specific to Linux (meaning the Linux kernel specifically, not the full GNU/Linux platform), as from here on much varies widely between different systems.
Starting in the mid to late 2000s, the Linux kernel started getting new and fun ways to lie to the processes it's managing. The last bits and pieces didn't fully work until as late as 2014 or even 2015, but by now they're fairly robust. Also, Linux is somewhat unique in that it implemented these features piecemeal, which allows programs to leverage them individually if necessary.
Most of these features fall under the umbrella term "namespaces." Similar to namespaces in mainstream programming languages, Linux namespaces provide a way to segment groups of processes from each other. More specifically, Linux namespaces allow the operating system to lie to different sets of processes in different ways about different things. And because processes are in a hierarchy, lying to one process also means lying to all of its child processes in the same way automatically (unless those have been moved to a different namespace explicitly).
Overall, there are six types of namespaces that the Linux kernel supports.
The UTS namespace
The simplest type of namespace is the one that controls the hostname of the computer. There are three system calls that a process can make to the operating system to get and set its name: sethostname(), setdomainname(), and uname(). Normally this just sets a global string, but by placing one or more processes into a UTS namespace those processes have their very own "local global string" to set and read.
In practice, your /etc/hostname file may say the computer's name is "homesystem," but by placing your MySQL process into a namespace you can make the MySQL process think the hostname is "database," while the rest of the computer still thinks it's "homesystem." That's right, it's easy to lie to a program about its very identity!
(Fun fact: The name UTS comes from the name of the struct in the source code that uname() uses, utsname, which in turn is an acronym for "Unix Time-sharing System.")
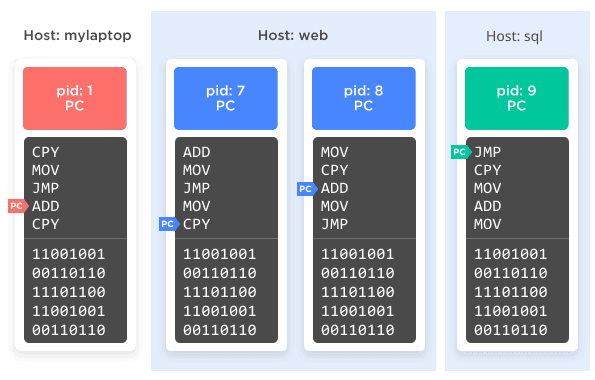
Figure 2
The mount namespace
The oldest namespace by far is the mount namespace, dating all the way back to 2002. The mount namespace lets the operating system present a different file system to a different set of processes.
The chroot() command, which has been with Linux since basically forever, allows a selected process (and its children) to view a specific subset of the file system as though it were the whole file system. These "chroot jails" were often used to try and segment a system so that certain processes were ignorant of what else was on the same computer. There is still one large file system tree, however. With a mount namespace, it's possible for there to be completely different file system trees that do not overlap at all running at the same time; each mount namespace sees, and can possibly modify, only one of those trees.
It gets weirder, too! Not only does that mean that for two given processes the root of the file system could be two completely different disk partitions, it means they could be two completely different disk partitions but also then both mount a third partition in different places in the two trees. Something kinda like Figure 3.
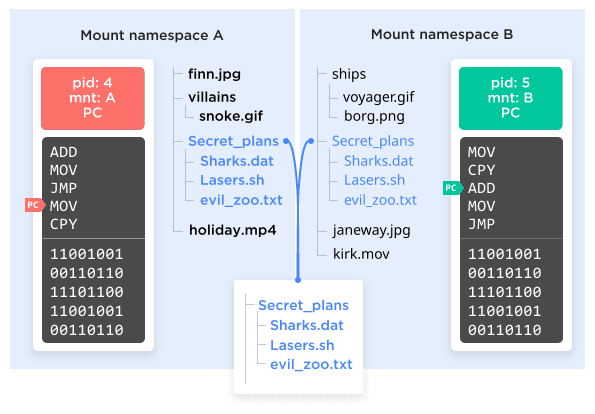
Figure 3
Also, bear in mind that any block device or pseudo-block device can be mounted into a file system. It could be a partition on a hard drive, but it could just as easily be a network drive on another computer, or a local removable device like a DVD or USB stick, or a file system image file that's sitting on... another file system.
The potential for lies and deception here is mind boggling...
IPC namespace
This one is a little obscure; recall earlier that we said processes could talk to each other through the operating system in various ways. Collectively that is known as Inter-Process Communication (IPC), and there are standard ways to do that. Most of them are really just message passing through queues, and in fact there are standard APIs in POSIX (the official standard that makes up any low-level *nix system) for them. IPC namespaces let the kernel separate those out, too, and deny access to some of those IPC channels to certain processes, depending on their namespace.
Process namespace
Now we get to the really interesting one. We said before that the process with PID 1 is always init, and all other processes are children of init, or children of children of init, etc. Every process gets a unique numeric PID to keep track of it.
You can have a look at the processes running on your system with the ps command. It has many possible switches and toggles, but we'll discuss just a few here.
Run ps -A to get a list of all processes running on the system. It should be a fairly long output, but if you scroll to the top of the list you will see a pid 1, with a CMD column that indicates what init program your system is using. For example, the beginning of the ps output for my Ubuntu system reads:
$ ps -A
PID TTY TIME CMD
1 ? 00:00:14 systemd
2 ? 00:00:00 kthreadd
4 ? 00:00:00 kworker/0:0H
6 ? 00:00:03 ksoftirqd/0
7 ? 00:05:36 rcu_sched
8 ? 00:00:00 rcu_bh
9 ? 00:00:00 migration/0
10 ? 00:00:00 lru-add-drain
11 ? 00:00:00 watchdog/0
12 ? 00:00:00 cpuhp/0
13 ? 00:00:00 cpuhp/1
14 ? 00:00:00 watchdog/1
15 ? 00:00:00 migration/1Although there's over 300 processes total. Running ps xf will show all processes for your own user and show the hierarchy of what process is a child of another process. Similarly, ps axf will show all processes for all users on the system, including their hierarchy.
That's very useful information, but there's a potential issue here: You can see exactly what processes any other user on the system is running! Is that a security issue? On your laptop probably not, but on any truly multi-user system it could be. Any malicious user (or a program by a malicious user) can trivially see what's running and its ID, which makes it easier to attack if the attacker knows another vulnerability to use.
Enter PID namespaces. PID namespaces are essentially what the name implies: They're a separate namespace for processes IDs. When you create a new PID namespace, you specify one process that will be PID 1 in that namespace. That could be another instance of your init program (systemd in the example above), or it could be any arbitrary process. That process may be known as PID 345 to the "global" namespace, but it's also known as PID 1 within its scoped namespace. If it then forks off another process, that process will also get two PIDs: 346 according to the parent namespace and 2 within its scoped namespace.
However, and here's the really important part, that process won't know about both PIDs. It's running in a namespace that has only 2 processes, and it will know itself as PID 2. That is the only PID it will know about, and if it asks the operating system for a list of all processes on the system it will see only those 2 in its own namespace (lie!). It cannot initiate communication with any process outside of its namespace. It doesn't even know they exist. A process from the parent namespace, however, can see and initiate communication with a process in the child namespace.
If that's hard to wrap your brain around, see Figure 4 for a visual version.

Figure 4
Of course, because so much of process management is managed through the /proc pseudo-file system, things can get weird if the process namespace isn't aligned with the mount namespace. Whether that's good-weird or bad-weird depends on how you set it up.
Network namespace
A network namespace is similar to the mount namespace, in that it allows for the creation of an entirely separate collection of resources. In this case the resources are network devices rather than a file tree. Unlike the mount namespaces, however, they cannot share these resources; a network device can be in one and only one namespace at a time. Moreover, physical network devices (those that correspond to a physical ethernet card or WiFi adapter) can only remain in the root namespace, and thus a new network namespace begins life with no devices at all, and thus no connection to anything. (Technically it has a loopback device, but even that is disabled by default.)
However, Linux can create any number of virtual network devices (lies!), which can be placed in a network namespace. Virtual network devices can also be created in pairs that essentially pipe from one to the other, even across a namespace boundary.
That allows for this clever bit of deception:
- Create a new network namespace, A.
- Create a pair of virtual network devices peered together. We'll call these
veth0andveth1. - Keep
veth0in the root namespace, and moveveth1in the new network namespace. - Assign
veth0the IP address 10.0.0.1 andveth1address 10.0.0.2. These two network devices can now connect to each other, because they're peered together by the kernel. - Assign one or more processes to this new network namespace, say, an nginx process.
That nginx process now starts listening to port 80 on veth1, address 10.0.0.2. Back in the global namespace we set up routing and firewall rules (e.g., NAT) to forward requests to port 8888 to 10.0.0.2:80. That will cause incoming requests on port 8888 to get forwarded through veth0 to veth1 on port 80, right to where nginx is listening for it.
See Figure 5 for the graphical version.
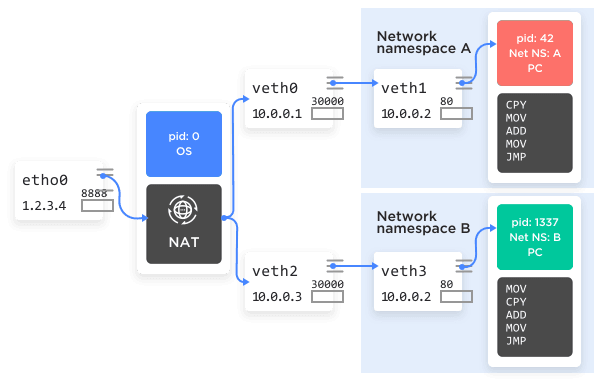
Figure 5
User namespace
Finally, the namespace that puts the icing and cherry on top. All processes, in addition to their PID, have an associated user and group. Those user and group markers, in turn, have an impact on access control; a process cannot force-kill another user’s process, for instance, unless it's owned by root.
With user namespaces, any process can now create a new user namespace, inside of which that process is owned by any user desired, including root. That means just as a process can have an in-namespace PID and an out-of-namespace PID, a process can have an in-namespace user that is distinct from its out-of-namespace user. And its in-namespace user can be root, which gives it root access to all other processes in the namespace, even if it's just an ordinary user process in the parent namespace. What's more, if a process is owned by root in the parent namespace then it can define a mapping of any users in the parent namespace to users in the child namespace.
If that paragraph made your brain flip over, you're not alone. Figure 6 may make it easier to follow.
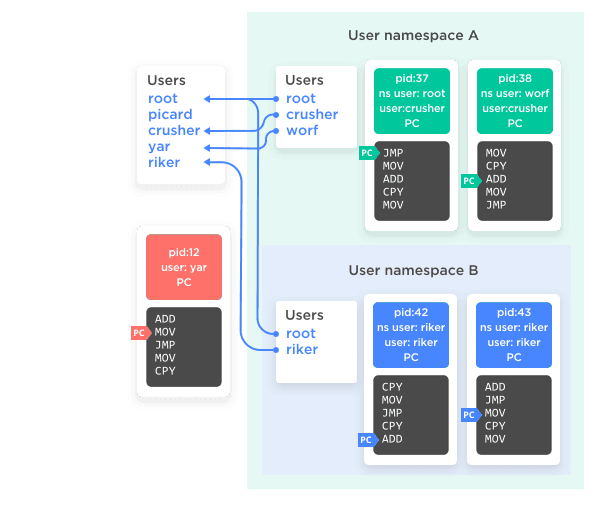
Figure 6
The important take-away here is that it's now possible for one process to have supreme root power over a select group of other processes, rather than all-or-nothing across the whole system. There are plenty of other conspiracies you can hatch to give processes both internal and external users, but selective-root is the really fun one.
Control Groups
The other piece of the puzzle is not so much about deception but about tweaking the scheduler. As we said before, the kernel, via the scheduler, switches different processes in and out of the CPU from time to time to simulate multi-tasking. How does it decide which processes are allowed to spend more time or less time on their CPU timeshare? There are many automated ways of allocating time more or less fairly, but they all assume that no particular process is going to be especially greedy. After all, a program can trivially break itself into multiple processes and therefore get extra pieces of the CPU pie.
The same applies to memory usage. The computer has a fixed amount of physical memory, and when programs fill it up with code and data the operating system will begin swapping seemingly less-used portions of it out to a scratch space on disk (called the "swap device" or "swap file," depending on the implementation). But that still means one greedy or inefficient program can elbow-out other processes simply by asking for lots of memory at once.
Control groups are the Linux answer to that problem. Control groups work by creating a parallel hierarchy of processes, independent of the creation hierarchy used by namespaces. Processes can then be associated with one and only one leaf in that hierarchy.
Any node in that hierarchy can have one or more "controllers" associated with it. There are a dozen or so controllers currently implemented, some of which just track resource usage, some of which limit it, and some of which do both. The two most important controllers for our purposes are CPU and memory, which can cap the total CPU usage or memory usage of a tree of processes.
So, for example, we can create a control group of processes, assign all of the nginx processes to it, and put a controller on it that limits its CPU usage to 25% and restricts them to two of the four CPU cores in the computer. Then we can make another control group, assign the MariaDB process to it, and restrict it to 100% of one of the remaining CPUs. Now, while it is still possible for a bad query to cause MariaDB to eat up all of its available CPU time, it won't impact the running nginx processes. They're segregated to different CPUs and limits on usage, so while MariaDB may slow to a crawl nginx will keep running, as well any other processes in the top-level control group. (See Figure 7.)
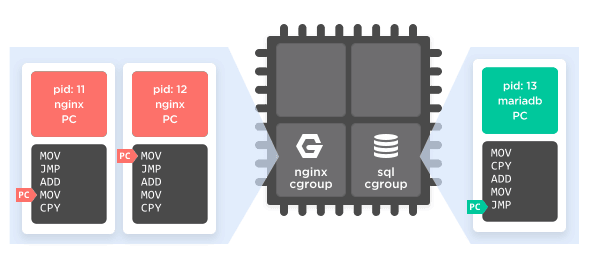
Figure 7
A process in a control group will still know that it's in a control group and that it's getting only a portion of the total system resources. Unless the process is owned by root, however, it won't be able to change that configuration.
Overlapping namespaces
An important point to note is that in Linux, unlike most older Unixes, each of these namespaces and control groups are distinct. It's entirely possible for processes 2, 3, and 4 to share a mount namespace, while process 3 is also in a user namespace and process 4 is in a UTS namespace. And then you can place processes 2 and 4 in a very CPU-limited cgroup together, while process 3 gets as much CPU time as it wants.
Such a configuration, while possible, is also quite complex. While some thoroughly fascinating functionality could result, it could also result in a completely unusable mess. More typically only a few namespace features are used to obtain very specific segmentation goals.
The most practical and applicable combination, though, is "all of the above!", as seen in Figure 8. Consider, we can now create a group of processes that:
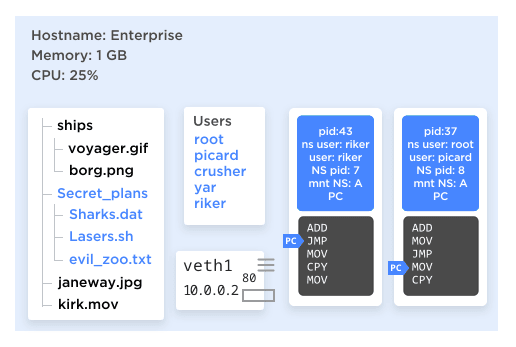
Figure 8
- Only know about each other, not any other processes on the system.
- Have one that thinks it has root access, and the other processes think is root, but doesn't have root on the whole system.
- Have their own file tree, from / on down, and no way to access any other file systems.
- Have their own host name.
- Have their own IP address they think they're running on, with their own set of ports, even their own IP routing rules for network access.
- Have no way of accessing processes outside of that group or even knowing that there are processes outside of that group.
- Will, collectively, use no more than 25% of CPU time and no more than 256 MB of RAM.
As far as a process in that group is concerned, what's the difference between that and running on its own complete computer? In practice, very little. It gives almost all of the isolation power of using virtual machines but with only a tiny fraction of the overhead; really, the only overhead is lookup tables for the kernel to keep track of what lies it's telling which process. The only limitation is that there's still only a single kernel instance running and controlling it all.
In fact, this "all of the above" combination of lies is so commonly desired that it even has a common name: Containers.
In the end, that's all a "container" is: It's a short-hand name for "use all the namespaces lies at the same time to trick processes into thinking they're running on their own computer when they're really not." And that ends up being extremely powerful.
Container abstractions
While the kernel offers all sorts of APIs to manipulate namespaces and processes at a fine-grained level, that is often not especially helpful when trying to build a system at a more coarse-grained level, such as a macro "container." As is common practice in programming, therefore, various other tools have sprung up to abstract those low-level APIs into easier to use higher-level APIs. There are many such systems written in a variety of different languages. Really, any language that is capable of issuing libc commands can work.
There are many such abstraction tools, all of which do more or less the same thing. A few you might have heard of are listed below.
- LXC (for LinuX Containers, written in C): https://linuxcontainers.org/
- Docker (written in Go): https://www.docker.com/
- lmctfy (short for Let Me Contain That For You): https://github.com/google/lmctfy/
- Rocket / CoreOS: https://github.com/coreos/rocket
- Vagga (written in Rust): https://github.com/tailhook/vagga
- Bocker (written in Bash): https://github.com/p8952/bocker
An even larger list can be found on https://dogger.io/, and at least Bocker is worth reviewing just to see how basic such a system can be.
Docker is by far the most popular such container management tool, although it is neither the first nor most recent. It just happened to be the new-and-cool option when the market decided it was "ready" for containers. Originally it was built as an additional layer on top of LXC, although it has since replaced its LXC dependency with its own library, called runC.
Although a bit more low-level than most end users and system administrators would like, LXC is one of the most powerful options. It also has bindings to further automate its capabilities using a variety of languages, including C, Python, Go, and Haskell.
Regardless of the tool, all are simply abstractions around saying "start a process, create a bunch of namespaces on that process, and mount this filesystem into it." That routine is generally called "starting" a container.
Orchestration
Another layer of abstraction that is often used is "orchestration." Orchestration is another abstraction layer on top of the container software. In a general sense, it's simply code that coordinates copying file system images between multiple computers, calling the container software on each computer and telling it to start a container, and then instructing the container software how to configure that container (namely, what details to set up for the various namespaces and cgroups).
In practice it's common to want to use multiple containers in tandem, communicating as if they were over a network when they're really just different processes on the same computer. Setting that up manually is mostly straightforward but very tedious. Orchestration systems automate the task of creating multiple containers and connecting them together with a nicer syntax. Kubernetes is the big name in this space right now but many other examples exist, including Platform.sh itself.
Read-only containers
It's very common for container implementations to encourage or require the use of read-only file systems. There are a variety of reasons for that. For one, it's simply very efficient. Linux is quite capable of taking a snapshot of a file system and producing a single file representation of it, which can then live on another file system. (Think of "ISO" filesystem images for CDs and DVDs. Plenty of other similar formats are available.) When creating a container, therefore, it's super easy to place its processes into a mount namespace, and then mount that file system image file as root within the mount namespace. Now, any process in the container, by which we mean in that mount namespace, will see that file system as the entire universe.
What's useful, though, is to make multiple copies of that container. Two different containers (that is, mount namespaces) can use the same file system image as their root mount point. If it's writeable, though, that raises all sorts of questions about how to synchronize writes between them. What happens if a process in one container makes a change that is important to a process in the other container? The answer is "it's messy."
If, however, that filesystem is read only, not only does it avoid any such synchronization issues, but it means the operating system needs only a single copy of it. Two, three, or 30 mount namespaces (containers) can mount the same 10 GB file system image on their root directory, yet the operating system need only read data off it once. And since it obviously doesn't need to load the entire filesystem into memory, that means the memory overhead for starting 30 containers with that same 10 GB file system is... a few KB of bookkeeping data inside the OS to keep its lies straight.
Take that, virtual machines!
Container portability
The marketing around containers often likes to make references to shipping containers, which revolutionized the cargo industry by creating standard-sized boxes that clumsier objects could be put into, which could then be neatly stacked on ships, trucks, and airplanes. The sales pitch often claims that a container is a standard format that can then run "anywhere," just like shipping containers.
That marketing, is, unfortunately, not only wrong but entirely backwards. It's yet another lie.
Generally speaking, the file system snapshots, or "images," that we discussed before are configured to only work correctly when loaded by one specific container abstraction library. They will often include not just a file system, but metadata that the abstraction library uses to decide what namespaces and cgroups to configure. Should this container have a network namespace that allows outbound access? On which ports? What additional file systems should be mounted? All of that metadata is in a library-specific format. A Docker-built image will not work on Vagga or LXC, and vice versa.
So if they're not really portable, what's the advantage?
The advantage is from the inside. Almost any meaningful program relies on hundreds of other programs and libraries. These are generally installed by the Linux distribution at known fixed versions... or at least mostly known and mostly fixed versions. They're patched all the time as bugs and security holes are fixed (or introduced). When people talk about "making production match staging," the long combination of possible versions of various libraries is what they're talking about. Even a simple hello-world PHP script relies on Apache or Nginx, PHP-FPM, the PHP engine itself, PHP extensions, C libraries used by those extensions, and likely a dozen other things. While in an ideal world the various different combinations of libraries would work fine, we all know reality is rarely ideal, and it can be maddeningly time consuming to find bugs introduced when the combination is different.
What containers give you is the ability to bundle all of those libraries up together into a filesystem snapshot. Almost invariably, one program (process) will start another by asking the operating system "start a new process using this file on disk." If the "disk" it knows about is a mount inside a mount namespace, and that mount is a filesystem image file, well, now you can tightly control the exact version of every dependency you put into that filesystem image. The one notable exception is the kernel itself. Everything else can be shipped along with your program.
It's like static linking your entire computer! Which means, yes, you're back to compiling things, even if writing in a scripting language like PHP or Node.
What containers really buy you is the ability to ship not your application, but your application and all of its dependencies, pinned at a precise version. When you then load that container on another computer, it will start a PID namespace, mount namespace, user namespace, etc., around the entire collection of dependencies you provide and (potentially) use cgroups to contain all of those processes to just a fragment of the resources on the actual hardware. That filesystem image can also be reasonably small, since you know what tools you're going to need and can include just those select few. The lie to your application is maintained; it doesn't know if it's running in a container or not, nor should it care.
That's also why languages that compile to a single executable like Go (or Rust, depending on your settings) are well-suited to container setups. They already bundle all of their dependencies into a single program, so the "filesystem full of dependencies" you need is trivially small: often it's just the program executable itself.
Because the overhead of each container is so small, running 50 copies of a container is no more expensive than running 50 copies of the same program without a container. With cgroups it's possibly cheaper and certainly easier to keep them from bumping into each other. That's in contrast to VMs where every instance adds not just a few running processes and some bookkeeping but completely duplicated copies of the Linux kernel, all user-space tools, and whatever program you are trying to run.
Containers at Platform.sh
There are numerous possible ways to set up all of this newfound flexibility, many of which are applicable in only certain situations. As a practical example, let's look at how our container implementation here at Platform.sh manages containers for customers and how it differs from Docker, which is widely used for local development.
Platform.sh treats container images as a build artifact. That is, what's in your project's Git repository is not what is deployed to production. Rather, we check out what's in Git, then run your "build hook" from the .platform.app.yaml file in your repository. That could include downloading dependencies with Composer, npm, Go modules, etc., as well as compiling Sass or Less files, minimizing JS scripts, or any other build commands you wish. The end result is just "a bunch of files on disk" on a build server.
That "bunch of files on disk" is then compressed into a squashfs file. Squashfs is a compressed, read-only file system that is itself a single file on disk, much like an ISO image. That "application image" is then uploaded, along with the metadata derived from your configuration files, to one of the many VMs we have running.
On the VM, then, we assemble a container. Platform.sh uses LXC, rather than Docker, as it offers more low-level flexibility, on top of which we have our own coordination and orchestration software. The first step is to create a new LXC container, which tells LXC to create a new init process (we use runit) with it its own mount, pid, UTS, network, and user namespaces.
In that mount namespace we then mount a base image, as defined by the aforementioned metadata. The base image is a squashfs file containing a minimal Debian installation with a user-selected language runtime and version: PHP 7.4, Python 3.8, or Go 1.14, for instance. That's now the file system that any process in the container (that is, in all of those namespaces) will see. And because it's a standard, common image, dozens of containers can be running on the same VM with almost no overhead.
Next, the user-provided application image is mounted at a standard location, specifically /app. That contains all user code, which obviously will vary between different projects but is generally far smaller than the entire rest of the shared OS image. Finally, the configuration metadata also defines various writeable mount points; those are part of a writeable network file system exposed for each container and mounted into the container's file tree wherever the configuration says to mount them. The result is a file system that consists of one widely shared squashfs image, one application-specific squashfs image, and zero or more network file mounts.
WIth the file system all assembled, the next step is setting up processes. If an application runtime requires extra configuration, those configuration files are generated out onto a small, writable ramdisk (again, limited to that mount namespace). For example, on PHP the php.ini file and PHP-FPM configuration will be generated into that directory. On a Ruby container it would be different files. All containers also include Nginx, so the nginx.conf file is written there as well. The base image includes symbolic links to where those configuration files will be, allowing the runtime to find them. (See Figure 9.)

Figure 9
LXC allows processes from the parent namespace to call into a container and execute an arbitrary command within the container (within all of the corresponding namespaces), which is how all of the control logic is built. The final step is to tell the init process inside the container to start the few processes it needs: SSH, nginx, and PHP-FPM if on a PHP container. A ps axf run from within one of these containers shows only the few processes that are part of the PID namespace of the container:
$ ps axf
PID TTY STAT TIME COMMAND
1 ? Ss 0:06 init [2]
72 ? Ss 0:06 runsvdir -P /etc/service log: .................................................................
78 ? Ss 0:00 \_ runsv ssh
105 ? S 0:00 | \_ /usr/sbin/sshd -D
20516 ? Ss 0:00 | \_ sshd: web [priv]
20518 ? S 0:00 | \_ sshd: web@pts/0
20519 pts/0 Ss 0:00 | \_ -bash
20605 pts/0 R+ 0:00 | \_ ps axf
79 ? Ss 0:00 \_ runsv nginx
99 ? S 0:00 | \_ nginx: master process /usr/sbin/nginx -g daemon off; error_log /var/log/error.log; -c /
104 ? S 0:00 | \_ nginx: worker process
80 ? Ss 0:00 \_ runsv newrelic
81 ? Ss 0:00 \_ runsv app
89 ? Ss 0:22 \_ php-fpm: master process (/etc/php/7.3/fpm/php-fpm.conf)That's it. The VM the container is running on will have thousands of processes running, but inside this PID namespace there's only ssh, nginx, and PHP-FPM for PHP 7.3, plus some small coordination processes that runit uses. The kernel will know those processes by both the pids listed above and some other system-wide PID, but from inside the container there's no way for us to find out what those are or even know that there are other processes, for that matter.
Finally, the coordination software instructs the OS to place all of these processes into a cgroup to restrict their collective CPU and memory usage. The level of restriction is based on the project's plan size.
That takes care of the application itself. A modern web application is more than just stand-alone scripts, though. Depending on the application it could include a MySQL or MariaDB database, MongoDB, a Redis database, Memcache, possibly a queuing server, and various other things. That's controlled by the services.yaml file in the repository. If the services.yaml files say "this project needs a MariaDB server, an Elasticsearch server, and a Redis cache server," then the coordination software will create three more containers, one for each of those services. The process is essentially the same as for the application container except there is no application image to mount. There's just a base image for the service (MariaDB, Elasticsearch, and Redis) and a writeable mount for the service's data files. Otherwise the process is identical.
Additionally, because each of those containers implies a new network namespace, none of them are able to talk to the outside world by default. Instead, virtual network interfaces are created that allow only whitelisted connections between the containers on specific ports, meaning the application container can talk to the virtual port 3306 on the MariaDB container, but no other port. And the MariaDB container has no way of talking to the Redis container or any container that doesn't connect to it first. And so on.
All told, the overhead of creating those four containers (meaning four UTS namespaces, four PID namespaces, four user namespaces, and four network namespaces) is minimal, maybe a second or two. Compared to the time of the processes themselves actually starting, copying the application image to the VM, and the coordination software's bookkeeping, it's basically a rounding error.
Because containers are so fast, being just a lookup table of lies, and because most of the filesystem is read-only, it becomes practical to handle new deployments the same way: Simply kill all of the processes involved and restart them. But we can be smarter about it, too. If, for instance, only the application code has changed, none of the backend services containers need to be completely terminated and restarted. Just the file mounts on the application container are updated to point to a new version of the application image. If a newer version of the base image is available (a new bug fix release of Node.js, for instance) or if the configuration changed and is now asking for a new version (to upgrade from PHP 7.3 to 7.4), then the application container is stopped completely and restarted with the new base image. In either case, the service containers don't need to do anything until their configuration changes as well.
Another advantage of the lookup table of lies is that creating multiple copies of a container takes only minimal extra time. Creating a new testing copy of the entire code base, services and all, is simply a matter of creating more namespaces for the kernel to lie about and mounting the exact same file system images again in the new mount namespace.
The way Platform.sh handles it is that every branch in Git corresponds to an "environment," that is, a set of containers for the application and related services. Any branch can produce an application image, which can then be mounted into a new container (namespace) with little additional resource usage.
The tricky part is the writeable filesystem for each container. That's handled by a volume-level copy-on-write process, conceptually very similar to PHP's copy-on-write way of handling variables in memory. That allows the data to be replicated to a new container (mount namespace) in essentially constant time, forking the data as it gets modified over time. That process is handled independently of Linux namespaces, though, so we won't delve into it here.
Also bear in mind that the Linux kernel is really really good at avoiding loading data into memory it doesn't need to. If there's 100 containers in 100 sets of namespaces, running 100 copies of nginx off of the same read-only file system image... Linux won't load 100 copies of the nginx binary into memory. It will load the parts of the binary it actually needs into memory once, and then when it lies to each process about its virtual memory space it will also lie to it about having its own copy of the application code. That means 100 copies of nginx don't take 100 times as much memory; they take maybe 25% more memory for each instance's own data. (The actual amount will vary widely depending on how much actual runtime data the application stores in variables.)
The net result is that a single beefy VM, running a single Linux kernel, can run dozens of user-defined application containers, dozens of MariaDB instances, a dozen Apache Solr instances, a smattering of RabbitMQ instances, and a Redis index or two, all at the same time; all of those applications will think, if they query the operating system, that they're the sole application running on their own computer; and all of them will be able to access only a select, whitelisted set of other "systems" (containers), in whitelisted ways.
All because Linux got really good at lying.
Contrast with Docker
Docker, by contrast, is set up to run a single process in each container (set of namespaces). That single process could be something like PHP-FPM, Nginx, or MariaDB, or a short-lived process like a running Composer command. Docker does not use an init process, so while it's possible to manually force multiple processes into a single container, it's not really the intended use case, and those processes will not start up and shut down gracefully if there’s a problem.
Docker also eschews the multiple-nested-mounts file system configuration in favor of a layered approach. Another Linux kernel trick is the ability to have multiple file system images "mask" each other. Essentially, multiple file systems can be mounted at /, and files in later file systems will get used instead of those in earlier file systems. That allows the common base tools of, say, a functional Debian or Red Hat system to live on disk only once and then get "masked" by an installed MariaDB or installed PHP-FPM overlay when the container boots. See Figure 10 for the visual.
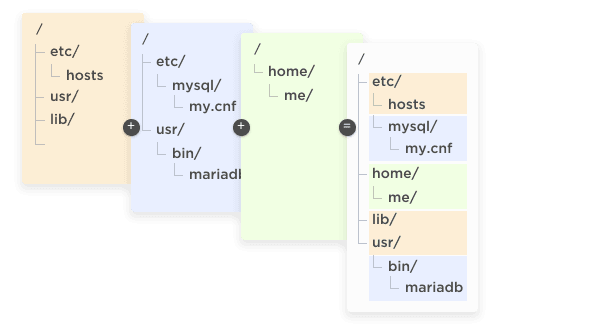
Figure 10
For Docker's main use case, running local applications in a container, that's perfectly fine. It's actually better suited to one-off tasks, such as wrapping a command line tool like Composer or NPM into a container, than Platform.sh's model. Platform.sh's design, in contrast, gives a more "VM-like" feel and allows multiple related processes (such as Nginx and PHP-FPM) to run together in the same container for simplicity, something Docker doesn't do. Neither model is inherently "better" or "worse," just tailored to different use cases.
The biggest difference is that Docker is inherently a single-container system; managing multiple containers in concert is left to separate tools such as Kubernetes, Docker Compose, Docker Swarm, and so on. In Platform.sh's case, the assumption is that containers will always be deployed as a group, even if a group of 1. (Recall Garfield's Law, "One is a special case of many.")
There are other container systems in the wild, too. RedHat's FlatPak or Ubuntu's Snaps are both container-based systems optimized for shipping desktop applications packaged up in containers. We won't go into detail about how those work as this article is long enough already, but be aware that those also exist and serve their own use cases better than either Platform.sh's hosting platform or Docker would.
The great thing about containers, as Linux implements them, is that they can be used in a wide variety of different ways depending on the use case. As with most things in technology, they're not good or bad, just a better or worse fit for a given situation.
Conclusion
While cool, and while they enable a host (no pun intended) of new functionality, containers are not magic. They're nothing like shipping containers at all, despite the marketing hype. Nor is Docker the first, last, or only container system on the market. There are a variety of container coordination applications around, all with their own pros and cons just like any other software market. Ultimately, all are simply organized and systematic ways to lie to your programs in new and creative ways.
Welcome to the future. Please keep your lies straight.
Special thanks to my colleagues Florian Margaine, Simon Ruggier, and Damien Tournoud for their help with this article. Graphics by Allison Simmons.
Further resources:
- Namespaces in Operation: https://lwn.net/Articles/531114/
- Many container resources: https://dogger.io/
- CGroups documentation: https://lwn.net/Articles/671722/





