 Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI
Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI Organizations, the ultimate way to manage your users and projects
Organizations, the ultimate way to manage your users and projects
Keep pace with evolving web application deployment best practices


[This post is heavily inspired by Christopher Skene's 2017
"Best practices" are often talked about in the tech world, but rarely is it acknowledged that they can and do change over time. All "best practices" are nothing more than a distillation of the challenges of a given situation to a usually optimal set of trade-offs.
As technology advances, however, those trade-offs change. What once was hard and expensive can become easier and cheaper. (And, sometimes, what was once easy and cheap can become hard and expensive.) That means "best practices" have to evolve with them. What was once leading edge is now a losing strategy.
The 3-tier web application deployment model
One example of such evolution is development workflows. In the olden days, server environments were expensive and time-consuming to build and maintain. They took physical hardware, manual installation of software, and manual maintenance to keep updated.
Once upon a time, that was justification for having only a production server, nothing else. That led to a common development model of "my desktop and production" (or "just production" if you weren't lucky). Anything more robust was too expensive and labor-intensive for all but the biggest installations.
Over time, we as an industry realized that it was a bad trade-off. "Hack it on production" got replaced with the famous 3-tier model (or sometimes a 4-tier model if you had the budget):
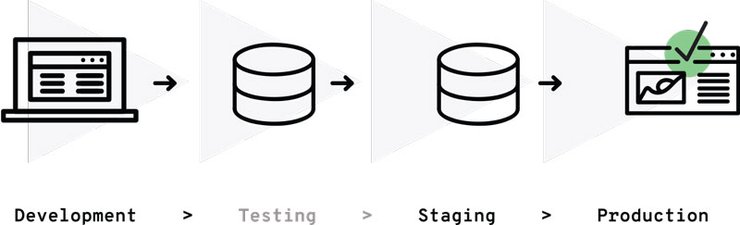
- Development is where code is edited, usually on each developers' local laptop.
- Testing is the first time multiple developers' code see each other. This is where integration testing, user-acceptance testing, and other QA happens. Sometimes this is merged with Staging.
- Staging is a pre-release holding area, to test code against a production-similar environment.
- Production is, well, production. The live site.
The advantage of the 3- or 4-tier model is that code has a chance to be reviewed and tested by multiple people before it reaches the live site. (As the joke goes, everyone has a testing server; some people are lucky enough to have a separate production server as well.) That's a step up from hacking on production, to be sure. It also means there is a discrete step where certain activity happens: code writing happens in dev; merging of code happens in Testing; QA happens in Testing; final review happens in Staging, sometimes with a snapshot of production data; and production is where customers actually view the site.
The catch with the 3-tier model in real-world web application deployment
The 3-tier model also has a number of drawbacks, however. In particular, it's really easy for local development to get far behind the Testing instance, leading to Testing becoming a mass of merge conflicts. The longer you wait to merge code to Testing, the harder it is to do. On the other hand, the more frequently you merge to Testing, the harder it is to test. The thing being tested can change every time some new code gets merged, leading to a moving target. That becomes an even bigger challenge when you have multiple testers, as their efforts may bump into each other. (That's particularly true when testing with end-users or tests that involve modifying data.)
The other major drawback of this model is that it is linear. For code to get to production, it must go through Testing and/or Staging, of which there is only one (each). That may be fine when everything is working, but of course, something always breaks. If you discover a bug in production, it's bad form to go around the test/stage pipeline and deploy straight to production without verifying that the fix doesn't break anything else. If you go through the proper test/stage phases, however, your simple emergency fix could get blocked by some other not-yet-ready feature that's already merged to Testing or Staging but yet approved for release.
That led to the idea of a "hotfix," which is developer-speak for "the process is getting in the way of fixing the bug, so I'm going to abandon the process." That may sometimes be the correct course of action, but it also demonstrates where the process is flawed.
Another problem is data. While code flows upward through the pipeline, you want to be able to test new code with current production data. Depending on the setup, the process for getting a snapshot of production data to Staging could be difficult and time-consuming. If it is, it's going to be even worse also replicating it to Testing or development. That means you may not find out how new code interacts with real data until the last minute, which is usually several weeks later than you'd like.
CI/CD for a faster process
The standard solution to the challenges of a 3-tier model is to push changes through it faster. That led to two twin concepts:
- Continuous Integration (CI), which roughly translates to "get code integrated into Testing as fast as possible."
- Continuous Deployment (CD), which roughly translates to "get code through the pipeline and deployed to production as fast as possible."
CI/CD, as it became known, tries to address the challenges of the 3-tier model with automation in order to get code through the process faster. That could entail a number of different options.
- Automatically running code-level tests on new code before it even gets deployed anywhere.
- Automatically running some QA or UAT tests in Testing, cutting down on the need for slow and over-busy humans.
- Automatically advancing code through the pipeline when certain criteria are met (such as tests passing).
That helps reduce the time it takes to push code through the pipeline, but it doesn't remove the core problem: The 3-tier model is linear, but code development is not. It also introduces its own challenges, namely more moving parts to have to set up, manage, and keep working. There are even specific job roles for CI/CD engineers, "DevOps engineers," or various other titles that essentially mean "care and feeding of all of this automation." That doesn't seem very automatic, but it can be costly.
Git and containers: CI/CD automation game-changers
Two technological advances made CI/CD automation tolerable.
The first was the widespread ubiquity of Git as a version control system. Git excels in many areas, but in particular, the extremely cheap and fast ability to branch code and merge branches greatly improves the "integration" part of the equation. Newer developers may not remember the days of Subversion or CVS, but before modern distributed VCSes "make a branch" used to be a hard, time consuming, and therefore rare task. Git solved that handily, and a straightforward API made it well-suited to scripting and automation.
The second was the advent of virtualization, first through virtual machines and then, even better, through containers. Containers allow you to abstract the idea of a computer "system" away from physical hardware. That meant building new environments didn't need to involve building new hardware, just sufficient coding.
For a long time, containers were used primarily for cheap Testing environments. CI services sprung up that used containers to build temporary mini-systems in which to run code-level tests, or sometimes full UAT tests. Combined with Git-based automation, that made the "Testing" stage of the traditional pipeline vastly simpler and more productive. In the ideal case, every Git branch, on push, gets any available automated tests run on it. If they fail, the developer knows immediately. If they pass, human reviewers can skip over the automatable parts and just evaluate the qualitative aspects of the new code.
Such services did not, however, resolve the core issue with the 3-tier model: its linear nature. It still just made it faster.
In addition, in most cases, the production system was still not in sync with development or Testing, and sometimes not with Staging, either. The closer Testing and Staging are to production, the more bugs can be caught early and the fewer variables there are to go wrong. Different versions of the operating system, dependencies, resource profiles, add-on libraries, language runtimes, and so forth all have their own subtle bugs lurking in each combination. If the combination in production is not the same as on Testing and Staging then those validation steps are just well-educated guesses.
The era of cloud computing
What virtualization, and containers in particular, really enables is the ability to not think about hardware at all. A computer "system" is no longer a hand-crafted artisanal thing that you maintain and have to manage. It's a logical, ephemeral, disposable creation in software.
Upgrading no longer involves changing software in place, but building a brand new "system" (container) and replacing the old one, a process that a good orchestration system makes completely transparent.
Ideally, the file system in each container is read-only, possibly with some white-listed exceptions for user data. That prevents both accidental customization and malicious security attacks. Rather than modifying the file system to make a change, you build a new file system image, throw away the old one, and activate the new one.
Being able to think about systems in a strictly software way is today called "cloud computing," a nod to the marketing term "The Cloud" to refer to hosted solutions generally. While not the same, they do go hand-in-hand. And as cloud computing environments are different from older, hardware-based systems, they have a new, different set of best practices.
Containerization: the best practice from start to finish
Each step along the way, the conventional "best practices" have changed. With the advent of widespread containerization, the leading "best practices" today are based on containerizing the entire process from start to finish. That, in turn, blows up the traditional 3-tier model.
Instead, today's best-practice web deployment strategy looks like this:
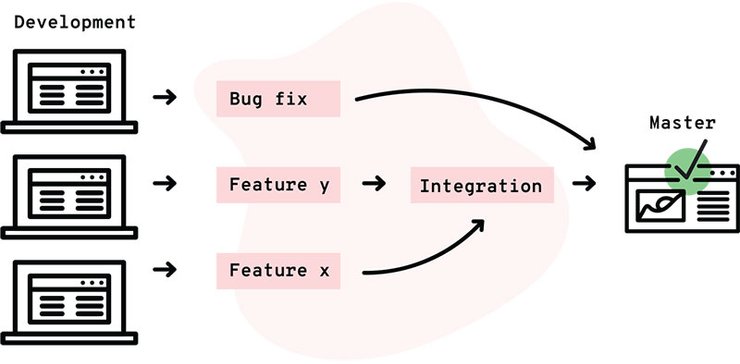
Every step from development through production is built with containers and managed through Git. Every branch corresponds to a container-based environment.
While development still happens on a developer's local computer, which may or may not be using the same container images, every other step involves bitwise identical containers. The version of PHP or Node.js or Java being used is guaranteed the same, down to the patch release and compilation settings. The version of your SQL database is identical. The version of your search server is identical. The third-party dependencies of your own code are identical.
And if they're not, it's because you have deliberately changed them. The configuration of the environment is itself code stored in Git, which makes testing infrastructure changes (upgrading a dependency or a database or your language runtime) the same as testing code changes.
You don't deploy new releases of your code; you deploy new releases of your entire system, of which your code is but one part.
All new updates to a Git branch can and should cause the corresponding environment to be rebuilt, from scratch, so there is no "update in place" question to consider.
App deployment scalability with Git-and-Cloud
This Git-and-Cloud model has a number of advantages over the 3-tier model.
- It's non-linear. One change cannot block another, because all changes have their own independent pipeline. A feature release, a critical bug fix, a routine update, all of them can proceed in parallel and deploy independently of each other, whenever they're done.
- The number of parallel lines of work is limited only by the number of containers you can create. Assuming you're using a virtualized cloud environment, that means your incremental cost for more environments is low and scales approximately linearly.
- Because every environment is disposable and built on the fly from repeatable instructions, your pre-release environments can be truly identical to production.
- "Integration" becomes just a question of how you want to use your Git branches. When a new change is merged to production, any other branch can easily merge updates from master, because Git makes that easy. If there's a conflict it will get caught immediately.
- Alternatively, you can also have a Git branch for pre-release testing that you merge other branches to in order to do integration testing there. That is, this model allows you to simulate the older 3-tier model if desired. That's usually not necessary, but available if it makes sense. The possible workflows are limited only by your team's skill with Git.
- Because the file system is read-only, you have guarantees that no changes can be made without going through Git and an extra layer of security to protect against intruders.
There are many possible tools to build a Git-and-Cloud hosting and deployment workflow for a modern application. Some are self-hosted while others are a hosted service. In most cases, a hosted service, such as Platform.sh, will offer better cost savings in the long run. The major drawback of the Git-and-Cloud model is the complexity of the underlying tooling that enables it, and that complexity is best handled by dedicated teams that can manage that tooling en masse.
New testing standards with Platform.sh
The icing on the cake, offered by only a few providers such as Platform.sh, is data replication. To really make a Git-and-Cloud model shine requires not just cheap environments and simple forward-flow of code, but also cheap backward-flow of data. The closer the data in your Testing environments are to production, the more accurate your validation and testing efforts. Platform.sh allows you to, with the click of a button, perform a copy-on-write clone of arbitrary data from one environment to another—no slow SQL dump and restore that could take tens of minutes or hours, potentially locking up the production instance in the process. It takes roughly constant time, in the range of one to three minutes on average.
That allows testing a new change—whether a small bug fix, a large new feature, or a dependency upgrade—with production data and production configuration for a few minutes or a few days. It provides the most precise "staging is like production" experience possible, while avoiding the concept of a "staging" server entirely.
That is today's leading-edge web deployment process.
Future-proofing the web application deployment process
As technology improves, the optimal use of technology changes along with it. 10 or 15 years ago, a 3-tier or 4-tier architecture was the industry standard process and what most organizations should have been doing. That was the "right way" at the time.
The tools have changed and so have the "best practices." Today, with the widespread availability of Git and cloud-computing environments, continuous deployment means something different than it did in the days of artisanal build processes. It means having an arbitrary number of parallel environments, non-linear workflows, and cheap, disposable containers that can be built from scratch on demand.
What will be the best practice in another 10 years? We'll find out when we get there.




