 Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI
Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI Organizations, the ultimate way to manage your users and projects
Organizations, the ultimate way to manage your users and projects


Microservices are a software architecture, where the systems are a collection of several independent services. Each service has a specific business focus and communicates with the others with a language-agnostic protocol, such as REST. The Eclipse MicroProfile initiative optimizes Enterprise Java for the microservices architecture. It’s based on a subset of Jakarta EE APIs. This post will give an overview of some best practices for working with Java microservices on Platform.sh.
Show me the context
To celebrate the Oracle GroundBreakers Tour through Latin America, we'll create a microservices architecture based on the context of the cities, sessions, and speakers where the Oracle GroundBreaker Tour is hosted.
Oracle Groundbreakers Tour - Latin America
- Chile – August 2
- Uruguay – August 5
- Argentina – August 6
- Paraguay – August 8
- Brazil – August 10
- Ecuador – August 13
- Colombia – August 15-16
- Panama – August 19
- Costa Rica – August 21
- Mexico – August 23
- Guatemala – August 26
- Peru – August 28
To manage the conferences into the Latin America trip, we’ll have three microservices:
- Speaker. The speaker service that handles the name, bio, and social media links for each speaker.
- Conference. The conference service that works with lectures, which handles the name, city, and year of the conference trip.
- Session: The session service that handles the name, title, description, and both conference and speaker information.
Databases
Each database has its proposal, structure, and particular behavior, so we'll use different databases according to each service. Indeed, that’s the advantage of microservices; each service can use any technology that conforms to its requirements without impacting the other services. Each microservice uses an appropriate database for its particular use case:

PostgreSQL (also known as Postgres). Free and open-source relational database management system that emphasizes extensibility and technical standards compliance. It’s designed to handle a range of workloads, from single machines to data warehouses or web services with many concurrent users.

MongoDB. Cross-platform document-oriented database program. Classified as a NoSQL database program, MongoDB uses JSON-like documents with schema.

Elasticsearch. A search engine based on the Lucene library. Elasticsearch provides a distributed, multitenant-capable, full-text search engine, with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java.
Eclipse MicroProfile implementations
The relatively new MicroProfile community dedicates itself to optimizing the Enterprise Java mission for microservice-based architectures. Their goal? A microservices application platform that’s portable across multiple runtimes. Currently, IBM, Red Hat, Tomitribe, Payara, the London Java Community (LJC), and SouJava lead the pack in this group.

Thorntail offers an innovative approach to packaging and running Java EE applications by packaging them with just enough of the server runtime to "java -jar" your application.

Payara Micro Less than 70MB in size, open source, lightweight middleware platform of choice for containerized Java EE (Jakarta EE)—microservices deployments requires no installation or configuration and no need for code rewrites.

KumuluzEE develops microservices with Java EE/Jakarta EE technologies and extends them with Node.js, Go and other languages. It migrates existing Java EE applications to microservices and cloud-native architecture.

Apache TomEE is the Eclipse MicroProfile flavor that uses several Apache Project flavors, including Apache Tomcat and Apache OpenWebBeans.
Join technologies together
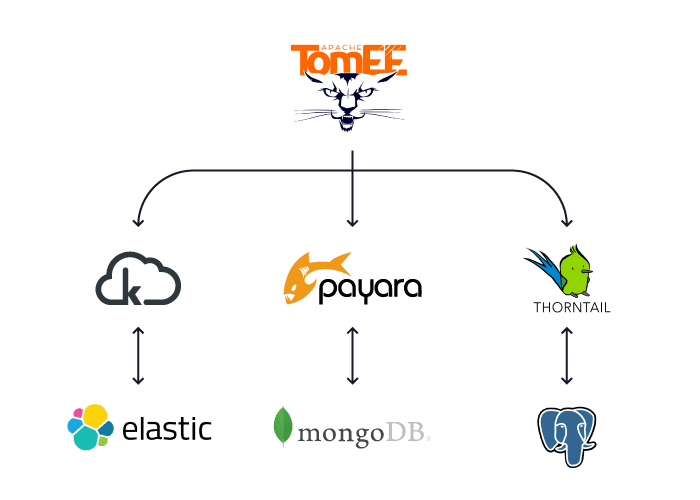
Our project has four components:
- KumuluzEE will handle the Session microservice. Users will want to search for session details, such as finding sessions that talk about either Eclipse Microprofile or Jakarta EE. To work with this requirement, the project will use a NoSQL that’s also a powerful search engine (yes, we're talking about Elasticsearch).
- Thorntail will handle the Speaker microservice, the most uncomplicated service that will manage the speaker information. This service will work with PostgreSQL.
- Payara Micro will handle the Conference microservice. This service is strongly related to KumuluzEE and Thorntail. To create a conference, we need both sessions and speakers. MongoDB seems to fit easily with this service because we can use the concept of subdocuments to put a list of presentations and speakers into the Conference entity, instead of making the relationship as in a relational database.
- Apache TomEE is the client browser using HTML 5 as the front end.
Eclipse MicroProfile and Jakarta to the rescue
The significant benefits of the Eclipse MicroProfile? Well, first, it uses standards on Jakarta EE, such as CDI, JAX-RS, and JSON-P.
To connect to PostgreSQL or any relational database, there’s a JPA specification that describes the management of relational data in applications using the Java platform. To communicate to the NoSQL databases, we'll use the Jakarta NoSQL specification (not a final version yet, but hopefully will come out soon).
On the client-side, we'll use Eclipse Krazo with an HTML 5 extension, using Thymeleaf as the template engine. At the moment, the client doesn’t have a database; it will only communicate with the services to organize the values, then show them in the browser. Therefore, it will use Eclipse MicroProfile Rest Client, which provides a type-safe approach to invoke RESTful services over HTTP.
Layers, layers, and more layers
The number of layers in an application is always a colossal discussion when we talk about microservices. Layers are essential to split responsibility and write clean code, while maintaining the several patterns built following this approach, like the MVC.
However, a vast number of layers is also hard to keep and to maintain; we need to pay attention to the delay layers. Otherwise, instead of an MVC, we're creating the onion pattern, where you cry each time you go through a layer. There is no magic formula to determine the number of layers you’ll need. Rather, it will be based on the complexity of the business rules, and how the infrastructure code can give us the cleanest architecture.
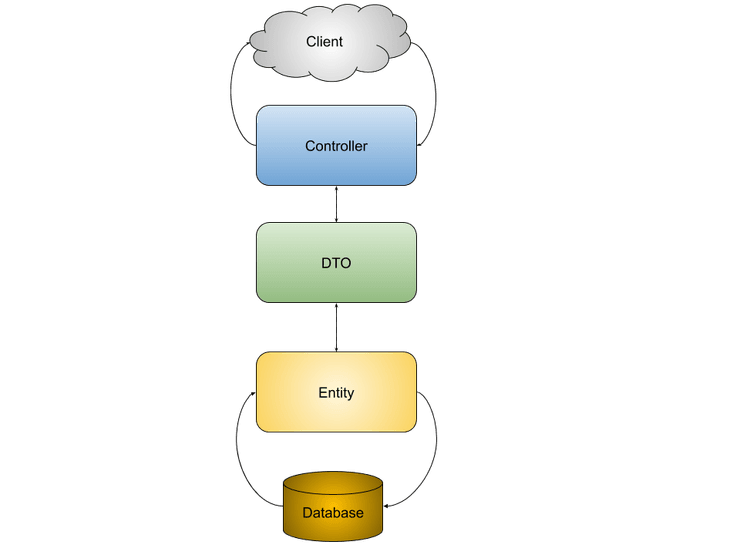
In our sample, we have three layers:
- The entity. The first instance of the business and where the domain lives. These entities, for best practice, should follow a rich model. We can make these entities agnostic to a database, but this time, let's keep it simple and use the entity highly coupled with the database.
- The data transfer object (DTO). Just a dump class to allow transfer values between the controller and the entity. Its most prominent goal is to prevent that entity from becoming an anemic model, because some frameworks might require getter and setter methods to serialization, which usually means weak encapsulation.
- The controller. The bridge between the view and the model. It only manipulates the flow among them. With some exceptions, it must be kept as clean as possible–you remember the high cohesion rule, right?
Is there a cloud? Or is there just someone’s computer?
Managing databases, code, and integrations is always hard, even on the cloud. Indeed, the server is still there, and someone needs to watch it, run installations and backups, and maintain health in general. And the twelve-factor APP requires a strict separation of config from code.
Thankfully, Platform.sh provides a PaaS that manages services, such as databases and message queues, with support for several languages, including Java. Everything is built on the concept of Infrastructure as Code (IaC), managing and provisioning services through YAML files.
In previous posts, we mentioned how this is done on Platform.sh primarily with three files:
One to define the services used by the applications (services.yaml).
elasticsearch:
type: elasticsearch:6.5
disk: 512
size: S
mongodb:
type: mongodb:3.6
disk: 512
size: S
postgresql:
type: postgresql:11
disk: 512
size: SOne to define public routes (routes.yaml).
"https://{default}/conferences":
id: conference
type: upstream
upstream: "conference:http"
"https://{default}/sessions":
id: session
type: upstream
upstream: "session:http"
"https://{default}/speakers":
id: speaker
type: upstream
upstream: "speaker:http"
"https://{default}/":
type: upstream
upstream: "client:http"
"https://www.{default}/":
type: redirect
to: "https://{default}/"It's important to stress that the routes are for applications that we want to share publicly. Therefore, if we want the client to only access these microservices, we can remove their access to the conferences, sessions, and speakers from the routes.yaml file.
Platform.sh makes configuring single applications and microservices simple with the .platform.app.yaml file. Unlike single applications, each microservice application will have its own directory in the project root and its own .platform.app.yaml file associated with that single application. Each application will describe its language and the services it will connect to. Since the client application will coordinate each of the microservices of our application, it will specify those connections using the relationships block of its .platform.app.yaml file.
name: client
type: "java:8"
disk: 800
# The hooks executed at various points in the lifecycle of the application.
hooks:
build: |
mvn -Dhttp.port=8888 -Dspeaker.service=http://speaker.internal/ -Dconference.service=http://conference.internal/ -Dsession.service=http://session.internal/ -DskipTests clean install tomee:exec
relationships:
speaker: speaker:http
conference: conference:http
session: session:http
web:
commands:
start: |
mv target/ROOT-exec.jar app/ROOT-exec.jar
java -Xmx1024m -jar app/ROOT-exec.jarWith the requirements set on the application YAML file, we can extract the information from the environment. Yes, we're following the twelve factors splitting the code from the config.
echo $PLATFORM_RELATIONSHIPS | base64 --decode | json_pp
{
"session" : [
{
"service" : "session",
"rel" : "http",
"scheme" : "http",
"cluster" : "dvtam6qrvyjwi-master-7rqtwti",
"port" : 80,
"ip" : "169.254.159.17",
"host" : "session.internal",
"hostname" : "owh4yp4z3tbt3x7fajdexvndpe.session.service._.eu-3.platformsh.site",
"type" : "java:8"
}
],
"speaker" : [
{
"scheme" : "http",
"rel" : "http",
"service" : "speaker",
"type" : "java:8",
"hostname" : "4edz7hoi7xx4bnb7vkeopzltc4.speaker.service._.eu-3.platformsh.site",
"host" : "speaker.internal",
"port" : 80,
"cluster" : "dvtam6qrvyjwi-master-7rqtwti",
"ip" : "169.254.245.54"
}
],
"conference" : [
{
"service" : "conference",
"rel" : "http",
"scheme" : "http",
"port" : 80,
"cluster" : "dvtam6qrvyjwi-master-7rqtwti",
"ip" : "169.254.81.85",
"host" : "conference.internal",
"hostname" : "3aora24tymelzobulrvgc5rscm.conference.service._.eu-3.platformsh.site",
"type" : "java:8"
}
]
}The good news about this information is that we don't need to manipulate or extract the data manually, and that’s why we have the configuration reader.
name: conference
type: "java:8"
disk: 800
relationships:
mongodb: "mongodb:mongodb"
web:
commands:
start: java -jar -Xmx1024m target/conference-microbundle.jar --port $PORTUsing the Java configuration reader, we can read from the environment and return a client such as MongoDB, Datasource, or Elasticsearch. For example, on the conference application.yaml, we require access to MongoDB, from which we can extract and convert this information into a MongoClient instance and make it available for CDI.
import com.mongodb.MongoClient;
import jakarta.nosql.document.DocumentCollectionManager;
import org.jnosql.diana.mongodb.document.MongoDBDocumentCollectionManagerFactory;
import org.jnosql.diana.mongodb.document.MongoDBDocumentConfiguration;
import sh.platform.config.Config;
import sh.platform.config.MongoDB;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Produces;
@ApplicationScoped
public class MongoConfig {
@Produces
public DocumentCollectionManager getManager() {
Config config = new Config();
final MongoDB mongo = config.getCredential("mongodb", MongoDB::new);
final MongoClient mongoClient = mongo.get();
MongoDBDocumentConfiguration configuration = new MongoDBDocumentConfiguration();
MongoDBDocumentCollectionManagerFactory factory = configuration.get(mongoClient);
return factory.get(mongo.getDatabase());
}
}Wait?! Where is the code?
To prevent this post from becoming a book, let's split it into a few parts. The first was an overview of the advantages of using microservices—why you should use them and how Eclipse MicroProfile and Platform.sh can help you make it happen. We’ve already talked about Eclipse MicroProfile, JPA, Eclipse Krazo, and Eclipse JNoSQL. You can review those posts, and, if you don’t care about spoilers, check out the code for this entire series on GitHub.
Otherwise, stay tuned for part two, where we’ll go down to the design of the code and explain it step by step.






