 Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI
Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI Organizations, the ultimate way to manage your users and projects
Organizations, the ultimate way to manage your users and projects

 I have been doing the REST style Micro-Services oriented architectures for the past seven or eight years now (seems it has become all the rage recently). And in many, many cases, I find it is a much cleaner, more robust approach than the traditional big monolithic option. We are not going to go into the implementation question of the services themselves but see what are some of the issues they present in terms of operations and workflow. For simplicity’s sake we will use a fictional example with a couple of services.
I have been doing the REST style Micro-Services oriented architectures for the past seven or eight years now (seems it has become all the rage recently). And in many, many cases, I find it is a much cleaner, more robust approach than the traditional big monolithic option. We are not going to go into the implementation question of the services themselves but see what are some of the issues they present in terms of operations and workflow. For simplicity’s sake we will use a fictional example with a couple of services.
Built upon micro-services
Platform.sh by itself is basically implemented in this style with very clear responsibilities for each element and strict rules on who can depend on whom. It is one of the things that guarantees our robustness: A distributed system does not try to prevent failure, but to limit its scope and give some guarantees on how the system functions as a whole when parts of it fail. The monoliths usually fail globally on any single part failing. And errors are part of life.
Built for micro-services
And as such, Platform.sh is also uniquely adapted to developing, testing, and hosting PHP applications in micro-services oriented style.
Platform.sh supports multiple applications in the same repository, so you can deploy in a single push your whole infrastructure with its underlying dependencies.
E pluribus unum
 But let’s first talk about micro-services. If you haven’t heard about this particular style of developing applications, well the gist of it is decoupling your web-app (or basically any application) and breaking it up into a number of small usually REST style APIs each with its own responsibility, the better implementations usually rely on hypermedia to stich everything back together into a coherent entity.
But let’s first talk about micro-services. If you haven’t heard about this particular style of developing applications, well the gist of it is decoupling your web-app (or basically any application) and breaking it up into a number of small usually REST style APIs each with its own responsibility, the better implementations usually rely on hypermedia to stich everything back together into a coherent entity.
This allows to follow the best practices of separation of concerns and the single responsibility principle and results in often not only better performance (you can easily fine tune caching strategies for each service) and simpler maintenance (you don’t need to update your whole stack just to update a single “function”) but more importantly better development velocity. The smaller the units you have to manage in an application, the more self contained they are, the more they have an explicit contract, the faster you can move without breaking everything.
Micro-Services are a graph on a grid
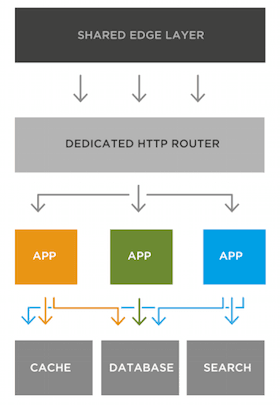 Another important element is that each service can come with its own infrastructure level dependencies. Your “image server” does not need access to the database. Your geolocation service might need a PostGIS, while your “user service” will be bound to you “main data store”, a MySQL or a PostgreSQL, you might want a traversal search engine such as Elastic Search. Separating dependencies is, again, extremely useful in ensuring the management of your whole thing is easier, its easier to swap out parts your infrastructure (you want to change from MySQL to PostgreSQL as your main store.. ? well, a single service depends on it).
Another important element is that each service can come with its own infrastructure level dependencies. Your “image server” does not need access to the database. Your geolocation service might need a PostGIS, while your “user service” will be bound to you “main data store”, a MySQL or a PostgreSQL, you might want a traversal search engine such as Elastic Search. Separating dependencies is, again, extremely useful in ensuring the management of your whole thing is easier, its easier to swap out parts your infrastructure (you want to change from MySQL to PostgreSQL as your main store.. ? well, a single service depends on it).
Sometimes the final consumer of these services will directly be a web application (angular style) sometimes it will be a traditional web application. Often it will be just another service. When you abstract away the underlying grid of backends and datastores it allows you to reason more simply about your whole architecture.
The Challenges
Over the years it has also become apparent to me that there are some unique challenges that arise from this particular style.
1. Operational Complexity
A first challenge is simply the operational complexity in sysadmin terms. Instead of having a single app-server and a single database you can find yourself with a myriad of applications written in different languages, having different constraints and depending on different back-end services. Sysadmins hate this. And when you do stuff like that by hand, they are right. More moving parts in a system that is not fully-automated means many more points of failure.
2. Dependency and version management
This is probably the big one: managing versions, because each service evolves at a different rhythm it makes ensuring the global coherence a complicated task:
Imagine I am working on a new feature for a front application, that requires modification in a couple of different services. All three (the front and the two services) will now be in flux.
One of the guarantees you really want to have is that you can deploy the different services at different times (remember… decoupling). Because having to deploy everything at the same time is basically a sure recipe for downtime.
Let’s imagine you have been good and not only you use hypermedia as your external versioning system, you use semver for your internal one. Let’s say the change we want to do is add an avatar to the user page, and let’s say the specs say it needs to be in grayscale. We did not have that field in the “user service” and our “image service” did not include the operation of transforming an image to grayscale. So three services will need to change.. the user service will get an extra field, so we need to change that in the model of the front app, and we need to add a capability to the image server. Our initial versioning scheme will be ImageServer 1.4.1, User Service 1.1.2 and Front 2.1.3 This change is just a single one in a more major refactoring of the front application with many other incompatible changes, let’s assume these do not affect our two services here.
3. Testability
We now from code that making small units with small scopes helps you write testable code. But with services this can be tricky. When you do your unit testing, you know you have checked-out a specific version of the code. Lock files let you know the precise versions of libraries you are importing.
And doing real integration tests on the services is hard because you usually would want to test them with their true dependencies, with the true network structure.
In our example, how could you test that the not only the current front (2.1) works well with the 1.5 and 1.2 but also its next minor releases (2.2) and their patch levels (2.2.1 etc..)?
And that’s the main problem with micro-services, testing each one might be easy… testing them together is hard!
4. Latency
If you only use HTTP to communicate between your services, and some of your services might have blocking IO behavior… the total latency of your system might very well become the sum of the latency of each. Which is very bad. This can be compounded by other elements like having to loop and make multiple requests in a single call.. or having a “Spaghetti style” services dependency model where everybody calls everybody all the time.
This is especially true in the case of PHP as it is hard to do asynchronous IO.
Platform.sh to the rescue!

Platform.sh is the first PaaS to support multiple applications each with their own dependencies as a single coherent cluster.
Each application is deployed to an isolated container. And you can describe which service has access to which other. You can in a single file describe the whole routing structure of the application.
The applications in the cluster are isolated, but can have access to commons services such as caches (like Redis), Message Queues (RabbitMQ, Kafka), Search Engines (like Elastic search) or simply SQL databases.
Asynchronous deployment allow for continuous deployment
We want to be able to release new versions of our Image and User services well before the whole version 3.0 of the front will be out; The earlier you will release your services the less chances you will have of “breaking something else”. Release Early, release often, and even better put: continuously deploy. In the world of Micro-Services the main issue is not backward compatibility but forward compatibility.
The smaller the different parts of an application you are deploying, the earlier you deploy, the less global breakage you are will probably cause. And the easier it will be to detect and correct production bugs.
As far as the User Service is concerned this is a schema change, but as we are only adding things so we are allowed to use a minor revision for the service. Next versions will be ImageServer 1.5 User 1.2 and Front 3.0. These are internal revisions we do not expose on the API, they do not change the endpoint.
With Platform.sh, you can deploy these multiple applications with their multiple backend services with a single command. You can backup the whole infrastructure, consistently, with a single command: and only the subtrees that were modified will get redeployed.
Let’s get nitty-gritty
In your git repo you can have multiple applications each with its own .platform.app.yaml that describes everything you want to for that particular service… and you can link them together by saying that an application or a service depends on another one.
Platform.sh will very conveniently expose in the environment of each service metadata such as the http endpoint for each other service, as well as all of the commons services they can communicate by.
Repository structure
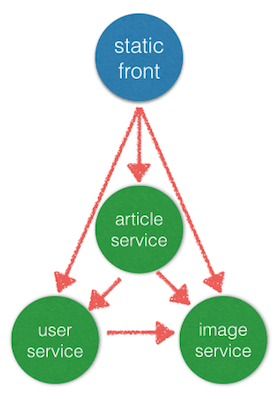 Even more conveniently each service can be in its own repository as a git submodule (or a subtree)!. The layout of your repository could look like:
Even more conveniently each service can be in its own repository as a git submodule (or a subtree)!. The layout of your repository could look like:
- image_api
- user_api
- front_app
In a real application we would probably have a couple of other services…
Each directory being its own git submodule and being a full web application, with its own .platform.app.yaml that can control everything, how much memory and disk space it will be allocated, which services it depends on, how should caching behave etc..
When you push your repo, platform.sh will resolve the whole dependency graph and take care of building your full infrastructure.
Configuring apps
If we look at each sub-directory (and in this case git repo) we should have at the root a .platform.app.yaml file.
Your image_api .platform.app.yaml file might look like this...
name: image_api
type: php:5.6
build:
flavor: composer
disk:1024
mounts:
"/tmp": "shared:files/tmp"
"/images": "shared:files/images"
web:
locations:
"/":
root: "public"
passthru: "/index.php"Your user_api .platform.app.yaml file might look like this:
name: user_api
type: php:5.4
build:
flavor: composer
relationships:
main_store: "database:mysql"
image: "image_api:php"
disk:128
web:
locations:
"/":
root: "public"
passthru: "/index.php"And your front .platform.app.yaml (this is an example of a static front using grunt for building) :
name: front
type: php:5.6
build:
flavor: composer
relationships:
user: "user_api:php"
image: "image_api:php"
article: "article_api:php"
dependencies:
nodejs:
- bower: "*"
- grunt: "*"
ruby:
- saas : "*"
disk:1024
mounts:
"/tmp": "shared:files/tmp"
"/images": "shared:files/images"
web:
locations:
"/":
root: "public"
index:
- index.html
hooks:
build: |
bower install
gruntDrums!
You can branch. You can have different versions of each component; And when you push… you get a fully functioning cluster. You want to test current front with Image Server 1.5, not a problem sir.
In your main repo directory just..
$ git checkout -b'next_release'
$ cd image_api && git checkout 'dev_1_5' && cd ..
$ git submodules update
$ git commit -am'test bleeding edge front with images server 1.5'
$ git pushAnd.. a brand new cluster will have been born (every service is redeployed with all of the backend stuff in place, with the same data as the parent environment, in the precise same state). You can now test all of that. And as always merging this to master is all you need to put the whole shebang into production. Because every service is injected in its environment all the information it needs on the other ones.. there is no configuration to be made.. the cluster is self-aware.
You want to test it now with user_api 1.2.2 ? cd image_api && git checkout 'dev_1_2_2' … you see the picture.
Conclusion
Platform.sh solves the four challenges of doing micro-service oriented architectures:
- Operational complexity: because every component is managed automatically with 0 sysadmin chores … there is no added complexity
- Version management: because Platform.sh treats the infrastructure as it treats code.. in Git.. you have very simple absolutely explicit version management, that can not be any simpler
- Testability: having resolved the two previous issues, testability becomesalmost a non issues, at any time you can deploy new clusters with mixed and matched versions, you can run those on your CI system and be guaranteed thatthe whole thing is running nicely… and will continue to run with the nextdeployment and the one after it..
- Latency: Platform.sh allows your components not only to communicate over HTTP but also using high throughput / low latency message queues, caching and search services. Per route caching also allows you to fine-tune the behavior of each service to optimize for freshness vs latency. As for the Spaghetti issue? well, that remains your responsibility. If you go for Italian this needs to be Lasagna. Or even a nice antipasti platter where everything goes together so tremendously well (I mean the Zucchini! wow. Just wow), but side-by-side.
Post-Scriptum. About money.

The last challenge with micro-services, is that you needed buckloads of money or an army of DevOps people to go that way. When you pay per server or per service.. it can add up to quite a hefty tab quickly. And if you need to manually containerize all the things.. that can take time.
With Platform.sh you don’t pay per application, just the global resources your whole project will use; With any other PaaS you will need to deploy multiple applications, and pay for each one separately.
And you have nothing to do to have each element deployed in its own container, and have the thing stitched back together. That’s our job.




