 Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI
Switching to Platform.sh can help IT/DevOps organizations drive 219% ROI Organizations, the ultimate way to manage your users and projects
Organizations, the ultimate way to manage your users and projects

You’re a cool kid who uses Git to manage the codebase of your applications because it’s convenient! You regularly create exact copies of your entire codebase by running git branch , pull requests to manage code review, use tags or branches to deploy to production. No doubt you host your Git repositories on GitHub/Bitbucket/Gitlab because, let’s face it, you are cool…
But you also get stuck every time you want to test a new feature, fix a bug that happens in production, or simply upgrade a service used in your infrastructure. Not so cool.

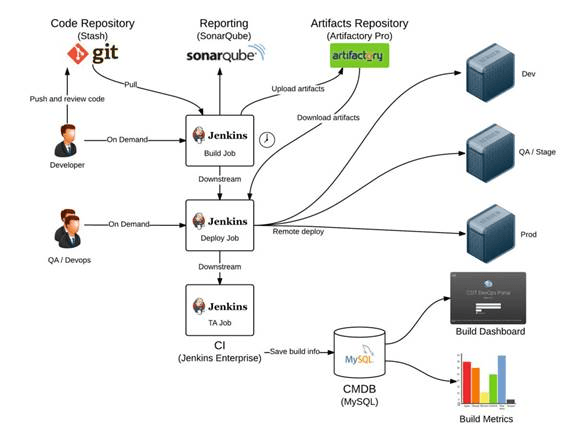
Alright, you might have access to some internal tools which perform some of the following tasks (kudos if they do them all):
- create development and staging environments on the fly
- quickly synchronize and sanitize production database to those development and staging environments
- migrate files between environments
- backup production environment
- deploy to production environment (and easily revert if things go wrong)
- manage permissions and access between environments
- …
Also, I’m pretty sure that it looks something like this (even worse sometimes):
I also suppose that you have someone (even possibly a team) responsible for maintaining those internal tools, making sure that they are properly running, up to date and always available for you to develop on…
Now, what if I told you that all of those processes can be as simple as running git push and that you, as a developer, can have 100% control of it? You can git branch the entire infrastructure as often as you need, and as many times as you need, to test and develop new features? You can also stay up to date with what is in production and so much more… without changing anything in your applications!

That’s what I mean!
With Platform.sh, the entire architecture, along with the build and deployment processes, lives in your codebase within your Git repository.
Any single change you make to your infrastructure (upgrade a service, add an extension, define cron jobs, …) will go through a Git commit so you can track it and know exactly what has been deployed, and where.
This configuration is defined as a simple .yaml file, which looks like this (Drupal in this case):
name: myapp
type: "php:7.0"
build:
flavor: drupal
dependencies:
php:
"drush/drush": "7.1.0"
runtime:
extensions:
- http
- redis
- ssh2
relationships:
database: "mysql:mysql"
solr: "solr:solr"
redis: "redis:redis"
web:
locations:
"/":
root: "public"
expires: -1
passthru: "/index.php"
disk: 2048
mounts:
"/public/sites/default/files": "shared:files/files"
"/tmp": "shared:files/tmp"
"/private": "shared:files/private"
"/drush-backups": "shared:files/drush-backups"
hooks:
deploy: |
cd public
drush -y updatedb
crons:
drupal:
spec: "*/20 * * * *"
cmd: "cd public ; drush core-cron"To summarize, the main advantage of this approach is to reuse software development best practices and tools to manage your infrastructure. Such as:
- Version control to know exactly what changes have been made
- Rollback to a preceding version of the infrastructure
- Testing the infrastructure on demand
- Making many small deployments as single steps instead of big, more painful, deployments
- Design patterns like continuous integration and continuous deployment
Watch Danilo Poccia session at Git Merge 2015 to learn more about this topic.




